一致性哈希
学习redis时,看到一致性哈希。
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简 单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的node中去,这样可以使得所有的node都得到利用。很多哈希算法都能够满足这一条件(即hash的结果应该平均分配到各个node, 这样从算法上就解决了负载均衡问题)。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的node中,又有新的node加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的node中去,而不会被映射到旧的node集合中的其他node(即在新增或者删减节点时, 同一个key访问到的值总是一样的)。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的node,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到node上时,由于不同终端所见的node集合有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同node中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性(即数据应该分散的存放在 分布式集群中的各个节点(节点自己可以有备份), 不必要每个节点都存储所有的数据)。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的node中,那么对于一个特定的node而言,也可能被不同的用户映射为不同的内容。导致同一个node被大量访问。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低node的负荷(即尽量将访问分散到不同node)。
为什么要一致性哈希?(why)
不使用一致性哈希时(不使用哈希或使用普通哈希),增减node几乎所有key的映射要重新维护。
使用一致性哈希时,key映射到固定数量的虚拟节点上,然后将虚拟节点的 哈希值mod(虚拟节点总数/节点数),来选取node,例如一个key哈希后值为28,虚拟节点40个,节点有5个,节点编号从1开始,则应该存放在node4 (28mod(40/5)+1=4),key值为39时则存放在node1,如下图所示: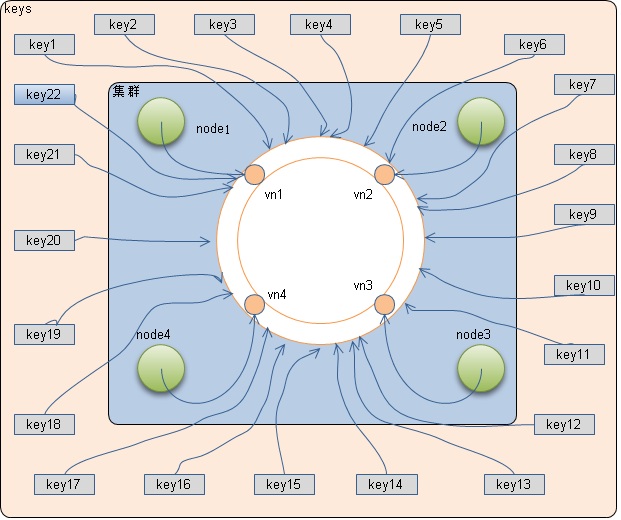
使用一致性哈希后,用节点将虚拟节点等分作为分割点,每次增减节点时只需要迁移每个分割点移动范围内的数据。
